It feels like every year the companies that contribute to building artificial intelligence have produced huge advancements that revolutionize the field of AI and 2025 is no different. It is quickly becoming one of the most important technologies in our generation so it makes sense to learn about how it is created and where future opportunities could exist. Historically, developing frontier AI models like ChatGPT xyz has been the exclusive playground of tech giants and specialized research labs with serious amounts of funding. The computational requirements alone—not to mention the technical expertise and financial resources—have created a walled garden, concentrating power among a select few organizations. So far, playing this game has not been for the every day anon.
The TLDR is when it comes to AI, we want to avoid having one company rule the world and yield the power of an ungovernable god.
Now the industry is seeing a new wave of techno-optimists working to decentralize AI development. This movement aims to distribute AI capabilities, benefits, and governance across a broader spectrum of participants, from lone researchers to collaborative communities. By reimagining how AI systems are trained, deployed, and monetized, these startups are working to create an AI ecosystem that's more open, accessible, diverse and hopefully performant.
My friend is immediately a cat
In this article, we'll dive into both the current state of large language model development and the emerging alternatives that could reshape the field. We'll start by examining how models like ChatGPT 3.5 come into existence—the staggering computational resources required and the bottlenecks that keep most players on the sidelines. Then we'll learn about three new companies—Prime Intellect, Nous Research, and Pluralis—each pioneering a unique approach to decentralized AI development. Finally, we'll explore how machine learning might evolve and the role decentralized approaches could play in that future.
Through this huge body of semi prompted text, we hope to give you a comprehensive understanding of both the challenges and opportunities in this rapidly evolving field—one that may fundamentally reshape not just AI development but the entire global economy.
02
THE MAKING OF MODERN LANGUAGE MODELS
The large language models powering today's most advanced AI systems represent one of the most remarkable technological achievements of the past decade. We think in 2 years they are going to power new multi billion dollar companies and we will spend most of our time talking to AIs instead of humans. It is hard to grasp just how important and impactful highly performant models will be for the economy and our everyday lives. Understanding how this technology is created can highlight where the current technology bottlenecks that exist and how decentralized AI can be developed to hopefully in time, surpass what centralized training methods can achieve.
THE ARCHITECTURE OF INTELLIGENCE
At its heart, large language models like ChatGPT 3.5 are a transformer-based neural network—a sophisticated architecture designed to process and generate human language. The transformer architecture, first introduced in the landmark 2017 paper "Attention Is All You Need" revolutionized natural language processing through its innovative attention mechanism, which allows the model to weigh the importance of different words in relation to each other.
In 5 years we will talk to AIs more than humans. I am already in that camp rip
This architecture enables the model to grasp complex linguistic patterns, understand context across lengthy passages, and generate coherent, contextually appropriate responses. The model consists of billions of parameters—adjustable weights and biases that determine how input data transforms into output predictions. These parameters form layers of interconnected artificial neurons, each contributing to the model's ability to process and generate language.
The scale of these models boggles the mind. While the exact parameter count of ChatGPT 3.5 isn't publicly disclosed, it likely contains tens of billions of parameters, each requiring precise adjustment during training. This massive scale is what enables the model's impressive capabilities but also creates enormous computational hurdles.
THE TRAINING PROCESS: A COMPUTATIONAL MARATHON
Training a frontier language model like ChatGPT 3.5 involves multiple stages, each devouring substantial computational resources:
The pre-training phase exposes the model to vast quantities of text data—hundreds of billions of words harvested from books, articles, websites, and other sources. During this phase, the model learns the statistical patterns of language by repeatedly predicting the next word in a sequence, gradually adjusting its parameters to minimize prediction errors. This process demands months of continuous computation on specialized hardware.
The fine-tuning phase adapts the pre-trained model for specific tasks or to align with human preferences. This includes supervised fine-tuning, where the model learns from examples of desired outputs, and reinforcement learning from human feedback (RLHF), where human evaluators rate the model's responses to guide further improvement. These stages add weeks or months to the development timeline.
The evaluation and testing phase ensures the model meets performance standards across various benchmarks and use cases. This includes testing for accuracy, safety, bias, and other critical factors before deployment.
Throughout this process, the model requires constant monitoring, adjustment, and optimization by teams of highly specialized engineers and researchers.
THE COST EQUATION: BILLIONS IN HARDWARE AND EXPERTISE
The financial investment required to train models like ChatGPT 3.5 would incinerate an Ohio based middle class family's bank account for generations. Industry estimates suggest that training a frontier model can cost anywhere from $10 million to $100 million or more, depending on the model size and training approach.
This cost is driven primarily by three factors:
Computational infrastructure: Training requires thousands of specialized AI accelerators such as NVIDIA A100 or H100 GPUs, or custom AI chips like Google's TPUs. A single A100 GPU costs around $10,000, and a training run might utilize thousands of these devices simultaneously. The electricity costs alone for a full training run can reach millions of dollars.
Data acquisition and preparation: Assembling, cleaning, and preparing the massive datasets required for training involves substantial labor and computational costs. High-quality data is essential for model performance, and ensuring its quality requires significant investment.
Human expertise: The teams developing these models include world-class machine learning researchers, engineers, and domain experts commanding high salaries. Their expertise is essential for designing model architectures, optimizing training procedures, and addressing the countless technical challenges that arise during development.
Beyond these direct costs, organizations must invest in the infrastructure to deploy and serve these models at scale, monitor their performance, and continuously improve them over time.
Own a GPU, save the world
THE BOTTLENECKS: WHY MORE ORGANIZATIONS DON'T BUILD FRONTIER MODELS
The enormous resource requirements for training frontier models create several critical bottlenecks that limit broader participation in AI development:
Computational bottlenecks represent the most obvious constraint. The specialized hardware required for efficient training is in limited supply globally, with leading AI labs and cloud providers controlling much of the available capacity. Even with sufficient capital, organizations may struggle to acquire the necessary hardware due to supply chain limitations and allocation priorities that favor established players. There has been some really interesting GPU consumption figures out of Singapore which highlights the geo-political tension around acquiring GPUs.
Data bottlenecks are equally significant. Training data must be diverse, high-quality, and free from problematic content, yet assembling such datasets requires substantial resources and expertise. The largest technology companies have natural advantages in data acquisition due to their consumer products and services, creating an uneven playing field for new entrants.
Expertise bottlenecks may be the most restrictive of all. The specialized knowledge required to design, train, and optimize frontier models is concentrated among a relatively small community of researchers and engineers, many of whom work at leading AI labs. This talent pool is growing but remains insufficient to meet global demand, creating fierce competition for AI specialists.
Financial bottlenecks naturally follow from these other constraints. The combination of hardware costs, data requirements, and talent needs creates financial barriers that only well-capitalized organizations can overcome. This limits innovation to those with access to substantial venture capital or corporate resources.
These bottlenecks collectively explain why frontier model development remains concentrated among a handful of organizations despite the growing importance of AI across all sectors of the economy. They also highlight why decentralized approaches to AI development have gained traction as potential solutions to these structural limitations.
03
PRIME INTELLECT
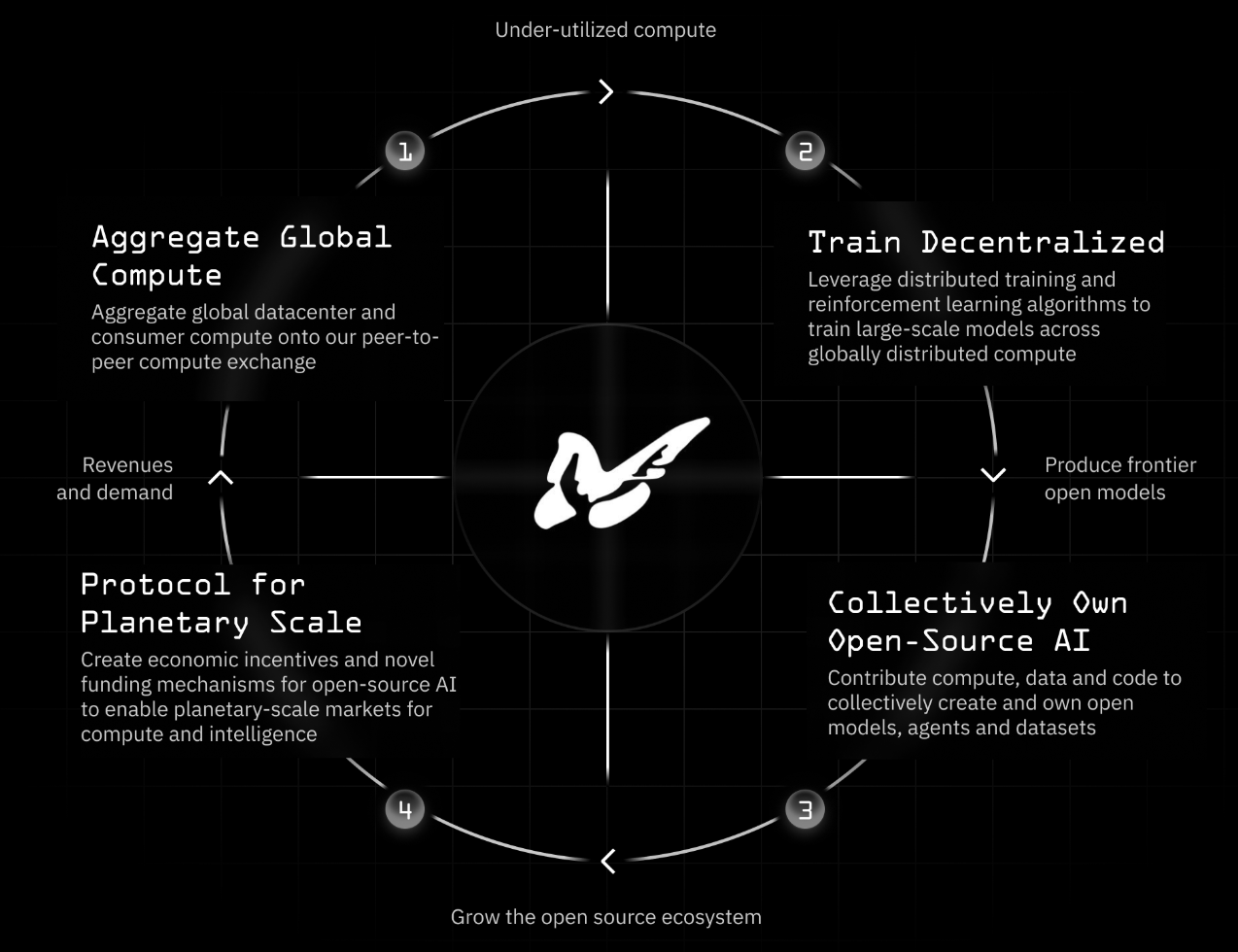
In the landscape of companies working to democratize artificial intelligence, Prime Intellect stands out for its innovative approach to distributed training infrastructure. Founded with the mission of making frontier AI development accessible to a broader community of researchers and developers, Prime Intellect is tackling a few of the most fundamental bottlenecks in AI advancement. Compute availability for training, building out open-source tooling to allow for decentralized training at scale and shipping their own large scale intelligence. They are a "full stack" decentralized AI company.
A MISSION TO DEMOCRATIZE COMPUTATIONAL POWER
Prime Intellect's founding vision emerged from a recognition that the centralization of AI development poses risks to innovation, diversity of perspectives, and ultimately the beneficial deployment of these powerful technologies. While many organizations focus on making AI more accessible through APIs or fine-tuning existing models, Prime Intellect has taken a more fundamental approach by reimagining how the underlying training infrastructure itself can be democratized.
They believe the future of AI shouldn't be determined solely by those with access to massive data centers. By distributing the computational load across a network of participants, Prime can create a more inclusive ecosystem where breakthrough innovations can come from anywhere.
Honestly just read this very logical master plan they published almost 12 months ago.
Imagine for a moment if they pull this off
This philosophy drives Prime Intellect's core technology: a distributed training platform that allows multiple participants to contribute computational resources toward training frontier AI models. Rather than requiring a single organization to invest tens or hundreds of millions of dollars in hardware, their approach enables collaborative training where participants can contribute resources ranging from individual GPUs to small clusters, collectively achieving the scale necessary for frontier model development.
Distributed training infrastructure in action
TECHNOLOGICAL INNOVATIONS
Prime Intellect's platform relies on several key technological innovations to overcome the challenges inherent in distributed training:
Prime Intellect developed a custom distributed training framework called PRIME. The framework introduced innovations like an ElasticDeviceMesh for fault-tolerant communication (nodes can drop in/out) and a hybrid parallelism approach (referred to as DiLoCo + FSDP2 with custom 8-bit compression for all-reduce). The result was a 400× reduction in required communication bandwidth between nodes during training, making it feasible to train over normal internet connections. Essentially, PRIME heavily compresses the chatter between GPUs, mitigating the usual network bottleneck of distributed training.
The company's secure computation framework ensures that participants can contribute to model training without accessing the full dataset or resulting model weights, addressing privacy and intellectual property concerns that might otherwise limit collaboration.
Their adaptive resource allocation system dynamically adjusts the distribution of computational tasks based on participant availability and capability, maximizing efficiency and resilience against node failures or disconnections.
These innovations collectively enable a new paradigm for AI development—one where the enormous computational requirements for frontier model training can be met through collaboration rather than centralization.
PROGRESS AND ACHIEVEMENTS
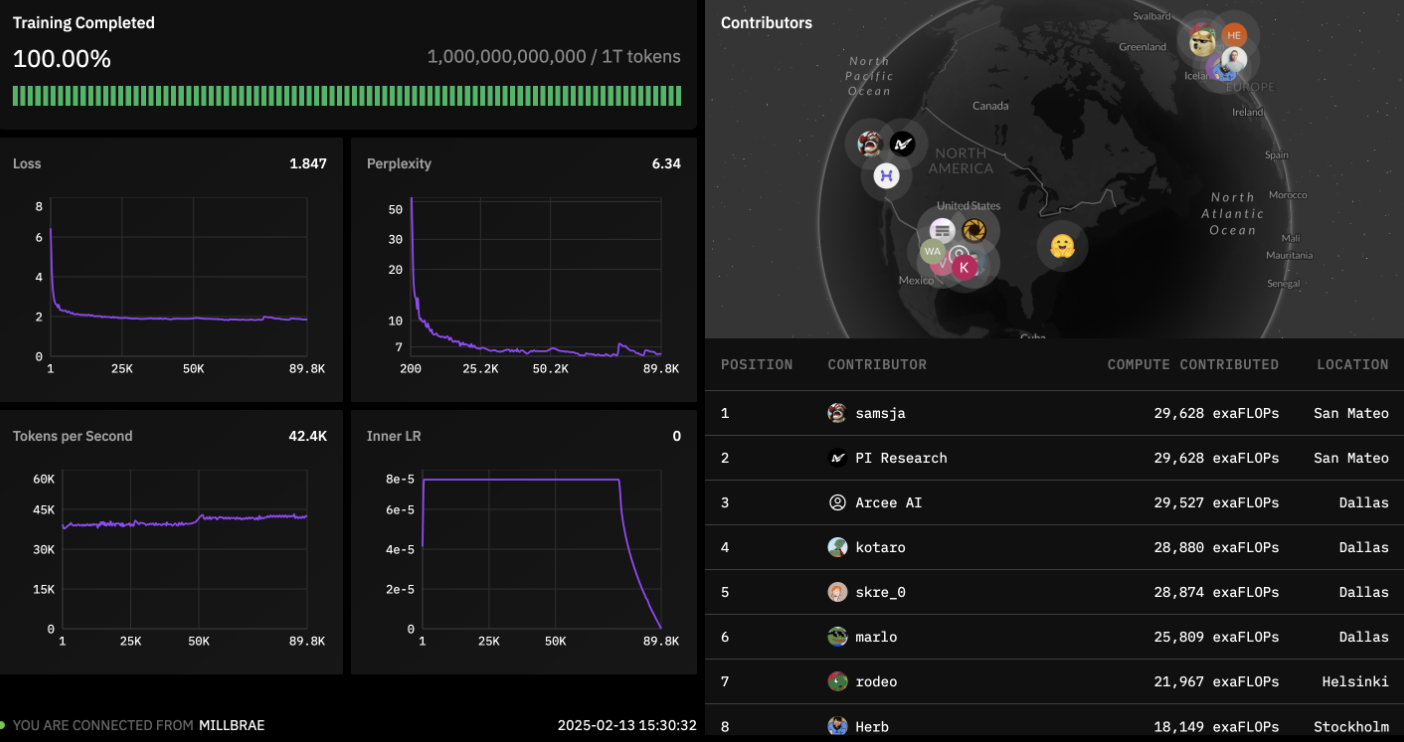
Prime Intellect has made significant strides in demonstrating the viability of their approach. Their most notable achievement to date is the training of Intellect-1, a 7-billion parameter language model trained entirely on their distributed platform with contributions from over 1,000 participants.
While smaller than models like GPT-4, Intellect-1 achieved competitive performance on several benchmarks, demonstrating that distributed training can produce high-quality models. More importantly, the training process validated Prime Intellect's core thesis: that frontier AI development can be democratized through collaborative approaches to computational resource allocation.
The company has also released Synthetic-1, the largest open reasoning dataset leveraging Deepseek-R1. The dataset specialized dataset focused on math and code generation, which they used to later train another model SYNTHETIC-1-7B-SFT. The model and training set produced strong performances in reasoning for code and maths and represents an important step toward specialized models developed through collaborative processes.
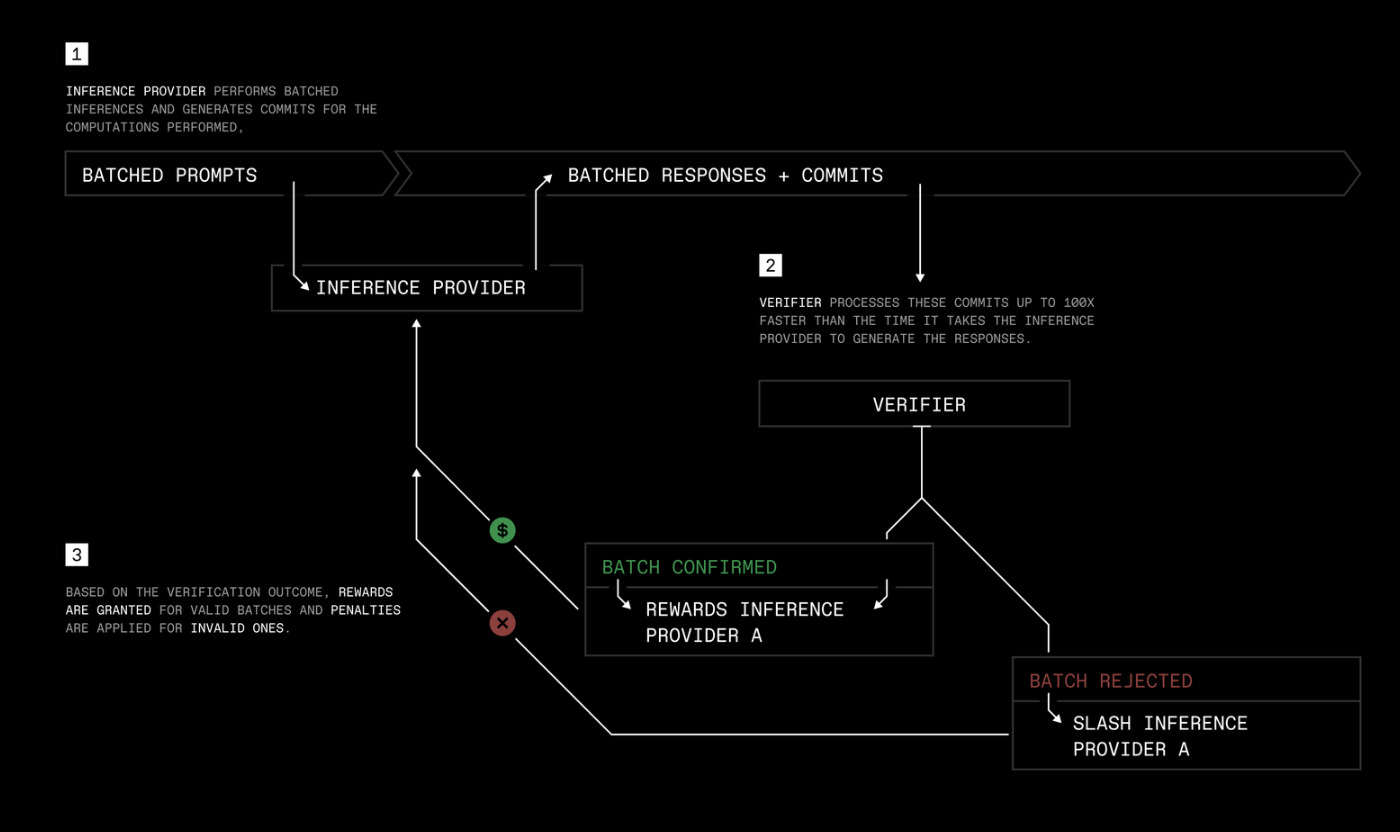
Beyond these models, Prime Intellect has developed TopLoc, an innovative technique that allows for greater trust that the correct LLM model is being used during inference. This technique, which reduces the memory overhead of generated commits during inference by 1000x (lord knows what that means, read the paper), has been open-sourced, is quite cool and is available to the public.
TopLoc: Enhancing trust in model inference
OPPORTUNITIES CREATED
Prime Intellect's approach creates several important opportunities in the AI ecosystem:
By proving that even a 10B-parameter model can be trained outside of a Big Tech data center, they hint that tomorrow's frontier models (hundreds of billions of parameters) might be attainable through pooled resources. This could dramatically lower the cost barrier for researchers and startups – instead of needing $10M up front, one could coordinate a network of volunteers or stakeholders each contributing a slice of compute.
It also suggests a novel business model: those who contribute to training could own a stake in the model's outputs. Prime Intellect explicitly talks about introducing economic incentives for community participation as they scale to larger models.
This might involve tokenized rewards or credits for contributors (though details are still developing). For AI infrastructure, this decentralized network is akin to a "cloud computing cooperative" – potentially offering an alternative to renting from AWS or Azure. If successful, it could spawn an ecosystem where many more players can experiment and innovate at the top end of AI, because the required compute is crowdsourced and the resulting models are open. If you have GPUs to contribute to their network, we would recommend check that out asap.
We think the major next step for Prime is training a model that is widely used and popular amongst the open-source community. In parallel they need to develop the business model because we would imagine it would be difficult to get a profitable margin as a compute provider when there are so many options on the market. Ultimately If they become a very popular compute resource for developers or ship excellent models to consumers like me, there will be lots of ways to make money through "pro" tool offerings.
04
NOUS RESEARCH
Nous Research shares a similar ethos about decentralizing AI, with an explicit focus on ensuring no single entity controls "superintelligence." They are developing Nous Psyche, an open infrastructure to democratize and decentralize the development of superintelligence for humanity. The belief here is that the development of extremely advanced AI ("superintelligence") should maximize individual freedom and agency, not be monopolized by a few corporations or governments. In practice, Nous is building a distributed training network powered by blockchain coordination. Founded by a group of AI researchers and Discord anons committed to transparency and accessibility, Nous Research has emerged as a leading force in the open-source AI movement, challenging the increasingly closed nature of frontier model development.
THE OPEN MODEL PHILOSOPHY
Curiosity drives all things good in technology
Nous Research was established on the principle that advanced AI models should be accessible to researchers, developers, and the broader public—not locked behind proprietary barriers. This philosophy stands in contrast to the trend toward increasingly closed and commercialized AI development, where the most capable models are available only through restricted APIs with limited transparency.
They believe that open models are essential for responsible AI development. Only through transparency can we collectively understand, evaluate, and improve these powerful systems, ensuring they benefit humanity broadly rather than serving narrow commercial interests.
The idea is that anyone with hardware – from a single RTX 4090 in a desktop to clusters of A100/H100 GPUs in a data center – can join the network and help train models, with the blockchain handling scheduling, trust, and (eventually) rewards.
This commitment to openness extends beyond merely releasing model weights. Nous Research advocates for transparency throughout the AI development process, including dataset composition, training methodologies, evaluation procedures, and known limitations or biases. This comprehensive approach to openness aims to enable more thorough scrutiny and collaborative improvement of AI systems that is not seen in the centralized giants in this industry.
THE HERMES MODEL SERIES
Nous Research's flagship achievement is the Hermes series of language models, which has demonstrated that open, collaborative development can produce models competitive with proprietary alternatives. The latest iteration, Hermes-3, released 8-, 70-, and 405-billion parameter models, which have earned attention for its strong performance across a range of tasks, from reasoning and knowledge retrieval to creative writing and coding. To get a sense of the demand of this kind of technology, Hermes-3 has been downloaded over 33 million times.
33m+ downloads of the model say less
What distinguishes the Hermes series is not only its performance but the transparent, community-driven process through which it was developed. Unlike proprietary models from well known corporations, every aspect of Hermes-3's development is documented in detail, from the composition of its training dataset to the specific techniques used for alignment and safety.
This transparency has enabled a virtuous cycle of improvement, with researchers from around the world contributing refinements, identifying limitations, and suggesting enhancements. The result is a model that not only performs well but also reflects a diversity of perspectives and priorities beyond what any single organization could achieve.
The Hermes series has been particularly notable for its efficiency, achieving performance comparable to much larger models through innovative architectural choices and training methodologies. This efficiency makes the models more accessible to researchers and developers with limited computational resources, further advancing Nous Research's mission of democratization.
IMPACT AND OPPORTUNITIES
Nous Research's work has created significant opportunities for democratizing AI development and deployment:
By releasing high-quality open models, they enable researchers and developers to build upon state-of-the-art AI capabilities at a lower cost and with more freedom.
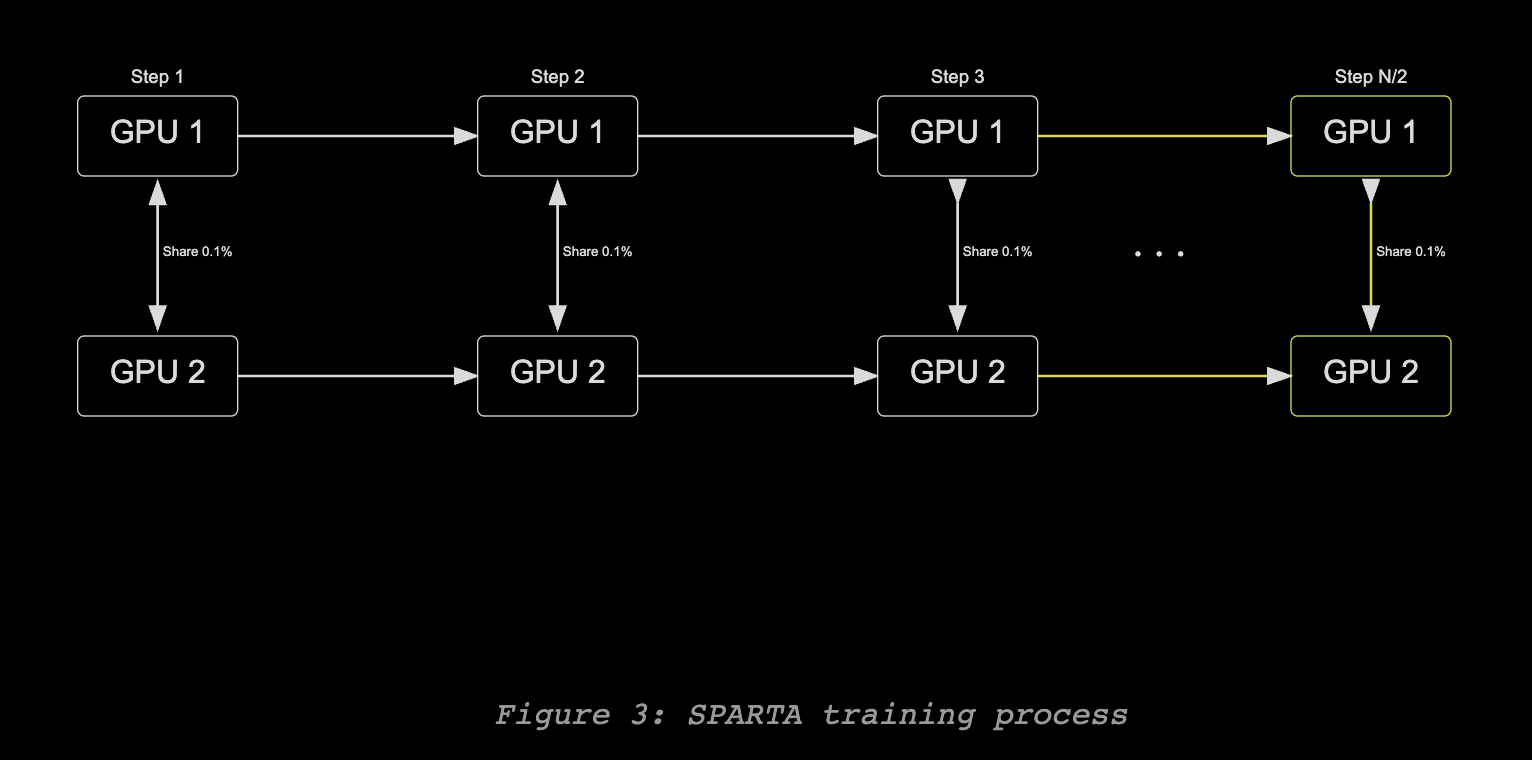
Infrastructure-wise, Nous developed Nous DisTrO (Distributed Transformer Optimizer), which is the backbone of their Psyche network. DisTrO massively reduces bandwidth requirements for multi-node training – reportedly compressing communications by 1000×–10,000× each step. This allows training runs to avoid needing ultra-fast interconnects; standard internet links suffice.
They demonstrated this in 2024 with a public test: using the Psyche system, they trained a 15B-parameter language model across a coalition of compute providers including Oracle Cloud, Northern Data, Lambda Labs, Crusoe Energy, and an academic cluster. During this test run, they achieved over 11,000 training steps, dynamically added and removed nodes during training, and showed zero impact from node failures on the overall run. In other words, their network handled the churn of nodes gracefully, and training even sped up as more nodes joined, all while maintaining stability. This is a strong proof-of-concept that a globally distributed, fault-tolerant training of a large model is feasible.
Their transparent approach to model development provides valuable educational resources for researchers. By sharing weights for their models, they help to expand and diversify AI research.
Perhaps most importantly, Nous Research demonstrates a viable alternative to the increasingly closed and commercialized approach to AI development that has dominated in recent years. By showing that open, collaborative methods can produce competitive results, they challenge the assumption that proprietary development is necessary for cutting-edge AI advancement.
As AI capabilities continue to advance and their societal impact grows, the model of open, transparent, and collaborative development championed by Nous Research offers a promising path toward systems that are not only powerful but also accessible, scrutinizable, and aligned with broader human values.
05
PLURALIS
While Prime Intellect and Nous Research focus on distributed computation and open model development, Pluralis represents yet another approach to decentralizing AI. Founded by a team of researchers with backgrounds spanning machine learning, distributed systems, and cryptography, Pluralis is developing what they call "Protocol Learning"—a novel approach that could fundamentally reshape how AI systems are trained, governed, and monetized.
PROTOCOL LEARNING: A THIRD PATH
Pluralis describes Protocol Learning as a "third path" for AI development—an alternative to both the centralized approach dominated by large tech companies and the purely open-source model championed by organizations like Nous Research. At its core, Protocol Learning envisions AI development as a protocol-governed process where diverse compute participants can contribute and benefit according to transparent, programmable rules.
"At a technical level, Protocol Learning is low-bandwidth, heterogeneous multi-participant, model-parallel training and inference." Blog This means that distributed training of a model with different types of compute is possible. The main difference in their approach is that they "shard" the weights on the model across the contributing GPUs so one participant cannot replicate the model and run away with the IP or monetizability of the innovation.
This approach draws inspiration from blockchain protocols, which enable decentralized networks to reach consensus and coordinate economic activity without central authorities. However, Pluralis emphasizes that Protocol Learning is not simply "AI on a blockchain" but rather a fundamental rethinking of how machine learning systems can be developed through distributed, incentive-aligned processes.
TECHNICAL FOUNDATIONS
The technical architecture of Protocol Learning rests on several key innovations:
The core innovation that Pluralis is exploring is sharding the model weights during the training phase so one participant doesn't have all of the weights for the model. When you look at OpenAI or other large corporations they may talk about the infrastructure or architecture around the model but they don't typically share model weights. Their approach follows the ethos that a model's weights are the keys to the model and should be decentralized.
Similar to Prime Intellect, Pluralis allows for a range of compute providers to contribute to a training run of a large scale model. They also believe the model ownership and access should be earned through providing compute.
Pluralis will also have programmable incentives for participants to create transparent, automated systems for rewarding contributions to model development based on factors such as computational resources, data quality, and algorithmic innovations.
These components combine to create a system where AI development becomes a collaborative process governed by protocols rather than organizations—potentially enabling more diverse participation while maintaining the coordination benefits of centralized approaches.
CURRENT PROGRESS
Compared to the other two decentralized companies mentioned in this article, Pluralis is in the early stages of development. They do not have much published yet beyond 3 blog posts but the team seems cracked, they just closed a funding round, are hiring for several roles and are hosting this event on Friday if you want to attend.
They have some innovative ideas like sharding model weights across decentralized training participants but time will tell just how much performance they will be able to achieve using this approach and how effectively a decentralized ownership model will be able to monetize and attract talent.
I think the core question for all of these companies is around their business model but just like earlier comments about Prime, if they build a model or a training process that is hugely popular there will be many ways to achieve financial freedom.
OPPORTUNITIES AND IMPLICATIONS
Down the road if Pluralis is successful, the Protocol Learning approach could create significant opportunities for democratizing AI development:
By enabling diverse participants to contribute to and benefit from AI development according to transparent rules, Protocol Learning could broaden participation beyond the handful of organizations that currently dominate frontier model development.
The programmable incentive systems could create new economic opportunities for data providers, compute contributors, and algorithm developers, potentially leading to more equitable distribution of the value created by AI systems.
Perhaps most significantly, Protocol Learning could enable a new paradigm where AI systems are developed not by individual organizations pursuing proprietary advantage but by diverse ecosystems of participants coordinated through transparent protocols—potentially leading to systems that are more robust, trustworthy, and aligned with broader human interests.
While Pluralis's approach remains experimental and faces significant technical and coordination challenges, it represents an exciting new development in this research field and could allow for a broader range of participation as model development becomes more common.
06
THE FUTURE OF MACHINE LEARNING
If you have made it this far, good job! There is no NFT to mint but we hope you enjoyed learning a bit about what is happening in this space. We learned about Prime Intellect, Nous Research, and Pluralis and how LLMs are created. Let's go a bit further and explore what could be next for this space.
THE EVOLUTION OF MODEL ARCHITECTURES
The transformer architecture that powers today's large language models represents a remarkable innovation, but it's unlikely to be the final word in neural network design. Several emerging trends suggest how model architectures might evolve:
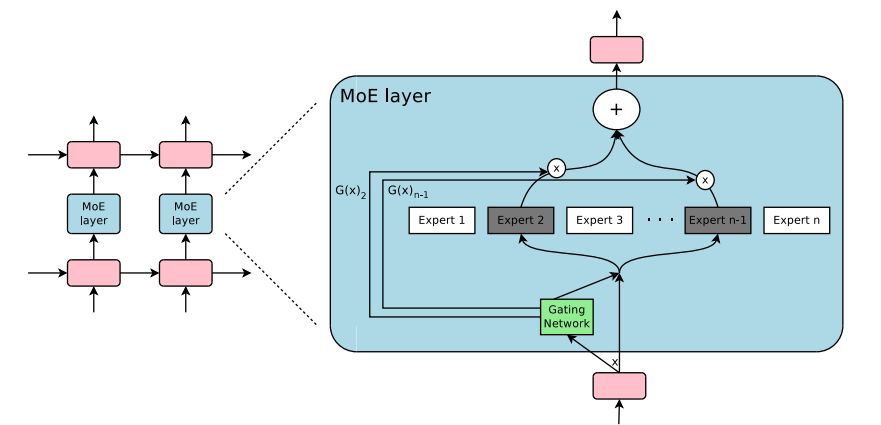
Mixture-of-experts (MoE) architectures, which activate only relevant portions of a model for specific inputs, are likely to become increasingly prevalent. These architectures can increase parameter count while keeping computational requirements manageable, potentially enabling more specialized and capable models. I am pretty sure this is how DeepSeek R1 was developed and it is partially why the Nvidia stock crashed after its release. There were some people that actually understand machine learning on Twitter saying DeepSeek like models would actually create more demand for GPUs, not less but we don't know the answer and we don't want to get arrested.
From the Hugging Face MoE Blog
Retrieval-augmented generation (RAG) approaches, which combine parametric knowledge (knowledge from the initial training run, like a textbook from 2015, is stored in model weights) with non-parametric knowledge (knowledge can be sourced from yesterday's NYT publication), will likely become more sophisticated. This could lead to models that more effectively combine the strengths of neural networks with traditional knowledge bases and information retrieval systems.
Modular architectures that decompose complex tasks into simpler components may address some of the limitations of monolithic models. Such approaches could enable more interpretable, controllable, and efficient systems by allowing specialized components to handle different aspects of a task.
These architectural innovations could significantly change the computational requirements for achieving frontier capabilities, potentially lowering barriers to entry and enabling more organizations to participate in advanced AI development.
DECENTRALIZATION OF TRAINING, DEPLOYMENT AND ECONOMICS.
The approaches to decentralization pioneered by companies like Prime Intellect, Nous Research, and Pluralis are likely to evolve and expand in several directions:
Distributed training infrastructures will become more sophisticated and accessible, enabling collaborative development of increasingly capable models. As these infrastructures mature, they could challenge the dominance of centralized training approaches, particularly for specialized models serving specific domains or communities. We will likely see specialized models for tasks from these companies. Prime Intellect has already done this with their synthetic reasoning dataset mentioned earlier.
Exo going for it
Open-source model development will continue to gain momentum, with community-driven efforts producing models competitive with proprietary alternatives. This trend could accelerate as architectural innovations reduce computational requirements and as more researchers contribute to open initiatives.
Protocol-governed AI development may emerge as a viable paradigm, enabling diverse stakeholders to participate in and benefit from AI advancement according to transparent rules. While still experimental, such approaches could eventually create new ecosystems for collaborative AI development that combine the benefits of decentralization with effective coordination.
Decentralized AI will create new economic models for the industry. Tokenized ownership of models is likely where these companies are headed. Imagine actually having a reason to own a token beyond the spiritual reason we still hold Ethereum. Community owned AGI could route the economic benefits of an AI model to a token. Participants that train and design the model could earn a token and consumption of the models inference (answers) could be accessed via a token.
Edge deployment of AI capabilities will become increasingly important, with models running locally on devices rather than in centralized data centers (ayo Exo). This shift could address privacy concerns, reduce latency, and enable AI applications in contexts with limited connectivity. We would assume Apple is heading in this direction but we don't really know. They seem to be a rocky start but you don't fade Steve's 5th child.
These trends collectively suggest a future where AI development becomes less concentrated and more distributed across a diverse ecosystem of participants—potentially leading to more innovation, specialization, and alignment with varied human needs.
CHALLENGES AND UNCERTAINTIES
Despite the promising potential of decentralized approaches to AI development, significant challenges and uncertainties remain:
Safety and alignment concerns may be more difficult to address in decentralized contexts, where coordination and enforcement of standards could be more challenging. Ensuring that increasingly powerful AI systems remain safe and aligned with human values will require innovative approaches to governance and technical safety.
Economic viability remains uncertain for many decentralized approaches, which must compete with well-resourced centralized efforts. Sustainable business models and incentive structures for decentralized AI development are still evolving and face significant challenges.
Technical limitations, particularly around efficiency and coordination, could constrain the capabilities of decentralized approaches relative to centralized alternatives. Overcoming these limitations will require continued innovation in distributed systems, cryptography, and machine learning.
If AI becomes one of the most important technologies of our generation the regulators will start banging their drums. They probably won't like decentralized companies because they can't control them as easily as the centralized option [DeFi probably has some stories to share] but we think this will be a bridge to cross once the technology and business model is already validated.
Despite these challenges, the momentum behind decentralized approaches to AI development suggests that they will play an increasingly important role in shaping the future of machine learning. Whether as complements or alternatives to centralized approaches, these decentralized models offer promising pathways toward a more open, accessible, and pluralistic AI ecosystem.
07
CONCLUSION AND NOTES FROM THE ANON
I think the TLDR from this article is that AI is already changing our lives in a huge way. One tangible example is this entire website and article was built and written by an AI. I just provided sources, prompted it 300 times, burned through an ungodly amount of credits and still had to rewrite most of the article but it was a cool process to experience. This is something I dreamed about when I was a 22-year old business man living in an old age home working from a windowless basement with a CTO who was building a product neither of us really knew how to make. While the AI like ChatGPT 3.5 is cool it is currently very centralized. The popular foundational models are owned by 2-3 major companies in California and this could be problematic down the road.
Decentralized training has had some major technology breakthroughs recently that allowed for companies like Prime Intellect to be created and can potentially create an alternative future for AGI. However, just like any new technology there are some huge challenges that need to be solved.
For example, assuming the more GPUs you have in your organization the better the model you can ship, decentralized training approaches have a long way to go to compete with OpenAI and their huge data centers. Even if you look the most popular models from Nous, they augmented the Llama model so they didn't have to do the huge expensive training run themselves to get the initial base model they needed. With the current status quo in model training, some organization still needs to pay millions in compute for a huge training run to get to a base level frontier model that others can build off of. This space is changing rapidly though as we have talked about with DeepSeek so who knows what the landscape and bottlenecks will look like in 24 months. As Nous and others raise more money they may want to explore building their own model from the ground up if it can be significantly better and there is a clear commercialization plan once it's created.
For fun let's think about a world where decentralized models win.
Imagine after a technological breakthrough from XYZ startup you can contribute compute with your MacBook. Suddenly everyone is training models while they sleep to pay rent and achieve UBI. Another hedge fund in China has some breakthrough on model design so training also gets much less resource-dependent due to MoE models being more performant than generic LLMs. Suddenly the compute problem is solved or at least competitive to OpenAI's data centers. Then you just have the specialized researcher issue, where only 100 autistic wizards are able to make progress on cutting edge model design and training methods. They almost all work for the big corporations. Over time this could be solvable because some of the best talent comes from far away places like Tigrinya in Ethiopia. They just don't have a visa to come to the US but they can contribute to Nous and get paid in token which they sell to USDT on Plasma, off ramp and buy a house.
Even if decentralized AI achieves 20% of what they set out to achieve it will still be a multi-billion dollar market and a nice counterbalance to centralized players.
If you want exposure to these companies you should work at them. If you can't do that you should contribute compute. If you can't do that you should join their discord and pray.
One notable mention that was left out of this post is Exo Labs. They are cool and allow for consumer devices to run AI models. Their technology is popular. If you want to learn about them dive in.
Till next time,
AphexTx
PS: There are likely many mistakes in this article because it was passed around a ring of AIs and then myself. I proofread it but I am busy and it is long. Please do not sue me.
PPS: If you want to write your own article, via an AI or any topic that is interesting to blockchains you can @ me on Twitter. If you are building a company or project in this space please reach out. I will probably invest 3 dollars and connect you to good people.
AI is a larger potential impact than anything we have created before